A focused, professional tool that does one thing exceptionally well: translate anything on your screen in real time using state-of-the-art AI.
🕹️
Simple & Custom Modes Free New v4
✨ The defining feature of version 4 ✨
Simple mode is designed for immediate operation – just pick your languages, position your overlays, and start translating.
Custom mode provides granular control over every aspect of the tool, allowing power users to fine-tune quality, performance, and cost.
🤖
AI-Powered OCR (Gemini & Gemma) Free
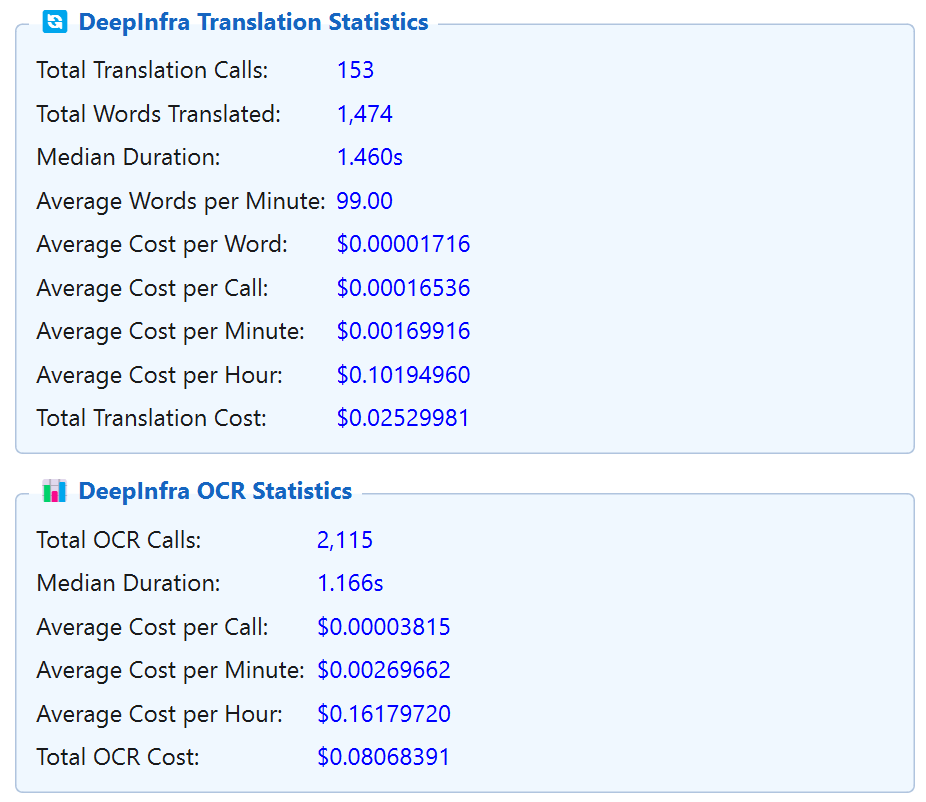
Industry-first AI text recognition. Use Gemini for ultimate precision or Gemma 4 (DeepInfra) for a high-performance budget option – delivering near-Gemini quality at 4x lower cost (~$0.16/hour for OCR).
🌍
AI Translation (Gemini & Gemma) Free
Multiple models for context-aware translation in 100+ languages. Choose Gemini 3 Flash for best results, or Gemma 4 (DeepInfra) for a fast, cost-effective alternative.
🎯
DeepL Translation PRO
High-quality, context-aware translation for over 100 languages. Delivers elite precision for Japanese, Chinese, and European scripts, as well as minority languages such as Welsh, Icelandic, Maori, and Burmese. Context subtitles are provided free and don't count towards your quota.
🧠
Sliding Context Window Free
Send up to 5 previous subtitles with every request. Maintains character names, grammatical flow, and narrative coherence across dialogue.
📊
Cost Monitoring Free
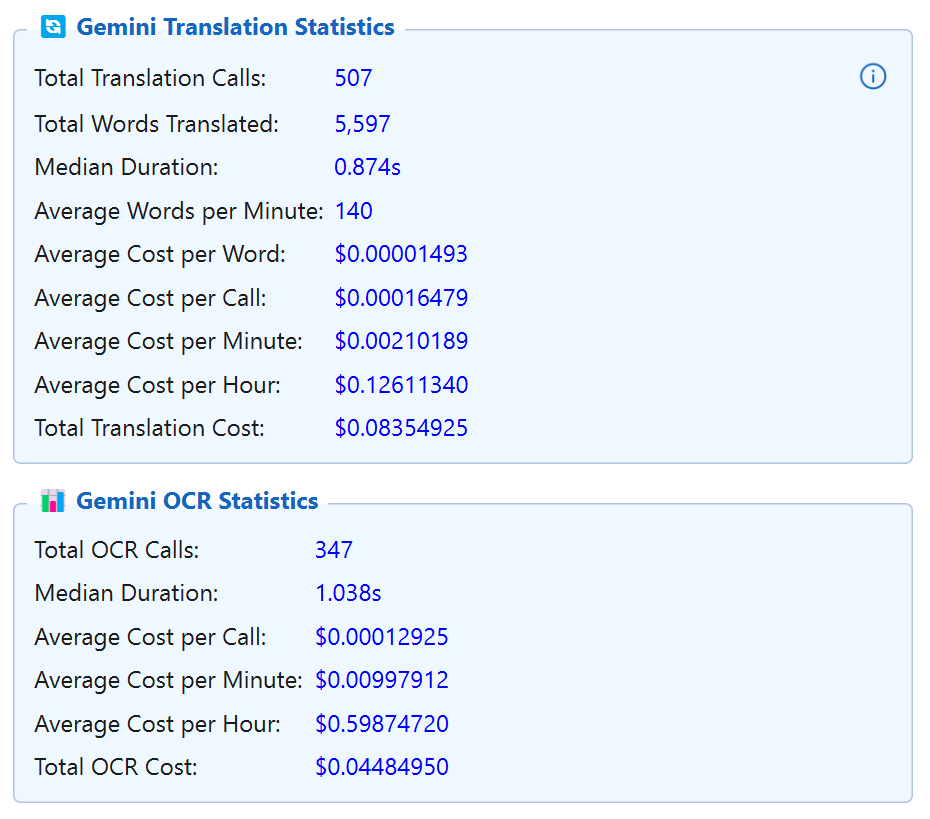
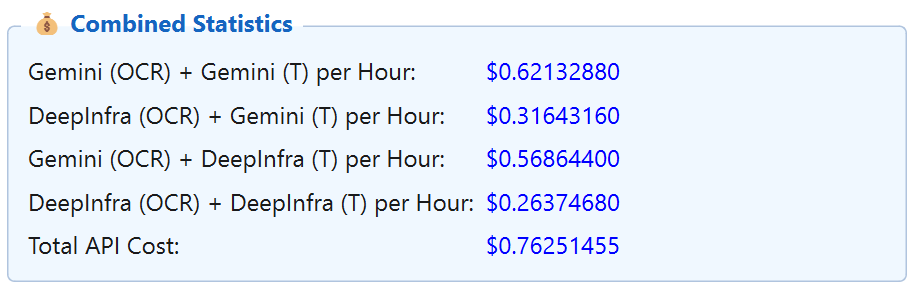
Real-time token-level analytics: cost per call, per minute, per hour, and cumulative cost for Google, DeepInfra and DeepL APIs.
⚡
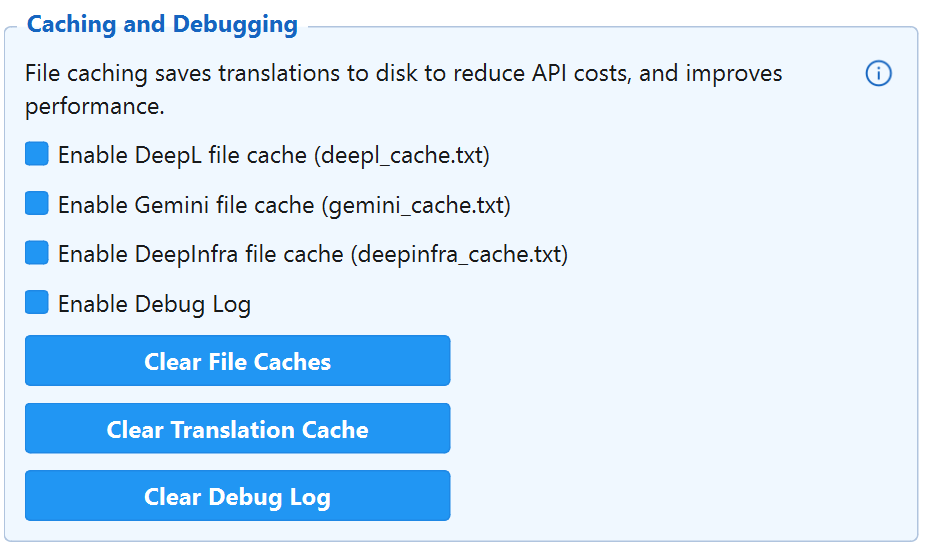
Two-Tier Caching Free
In-memory LRU cache + optional file cache. Repeated phrases cost zero API credits – retrieved instantly from the disk.
🔍
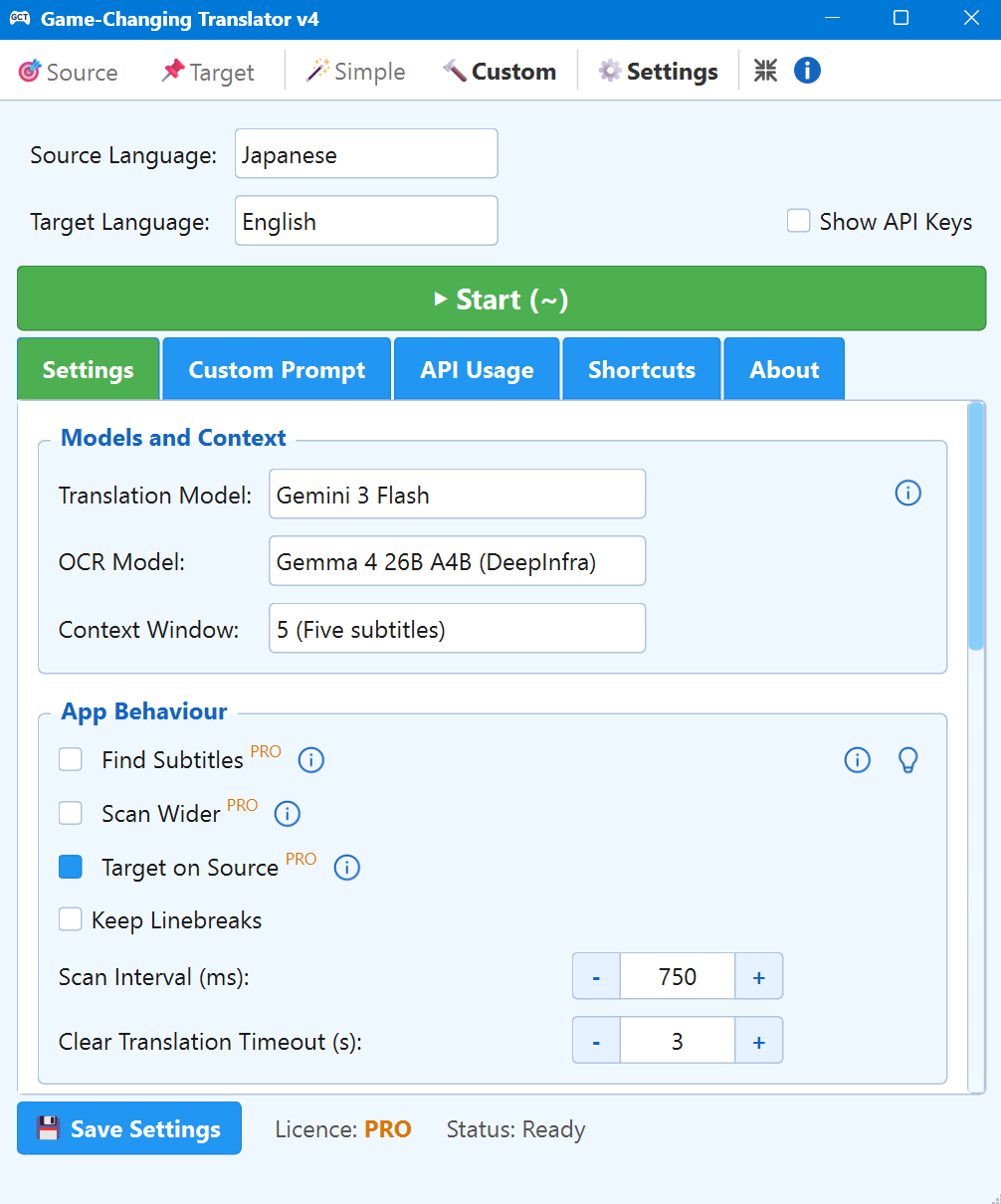
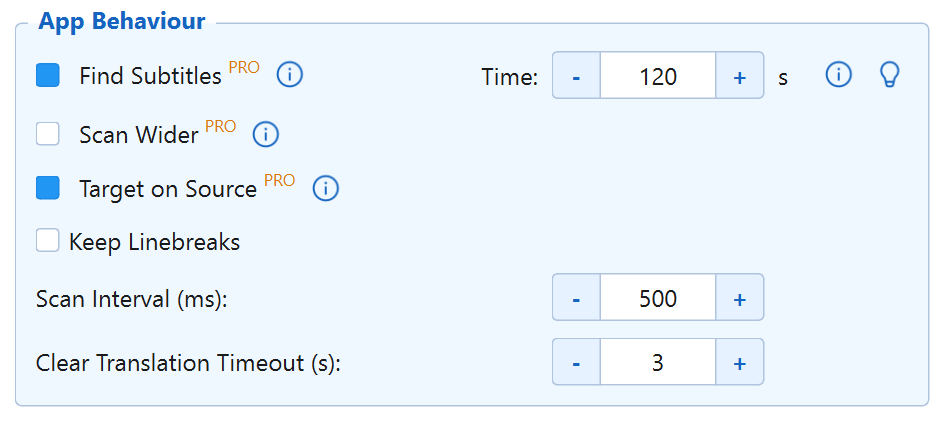
Find Subtitles PRO New v4
Automatically scans the full screen for a set period to detect where subtitles appear, then locks the capture area.
↔️
Scan Wider PRO New v4
Dynamically expands the OCR capture area to prevent edge-of-frame word truncation and AI hallucinations from tight crops.
🪟
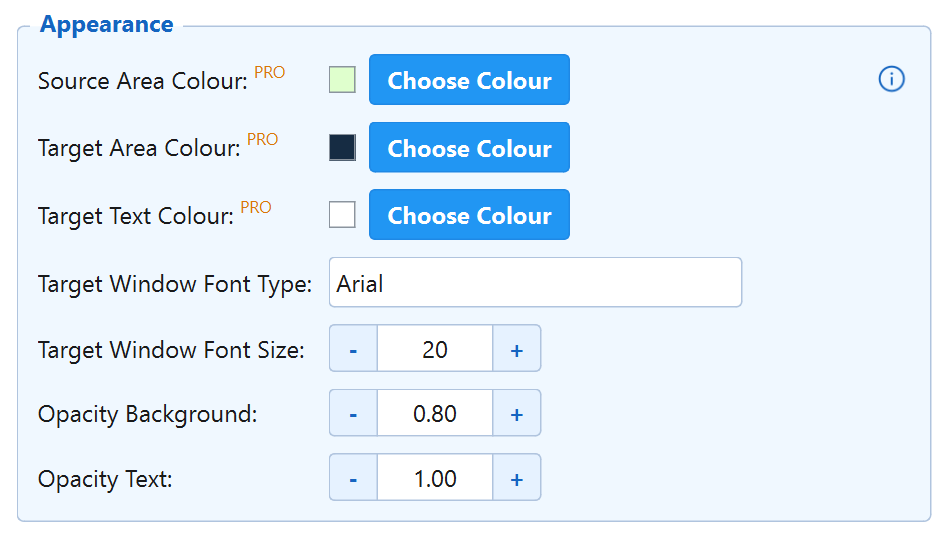
Target on Source PRO New v4
Automatically overlays the translation directly onto the original subtitle area for seamless, immersive reading. Even with this option disabled, a PRO user can drag the target window manually over the subtitles.
📝
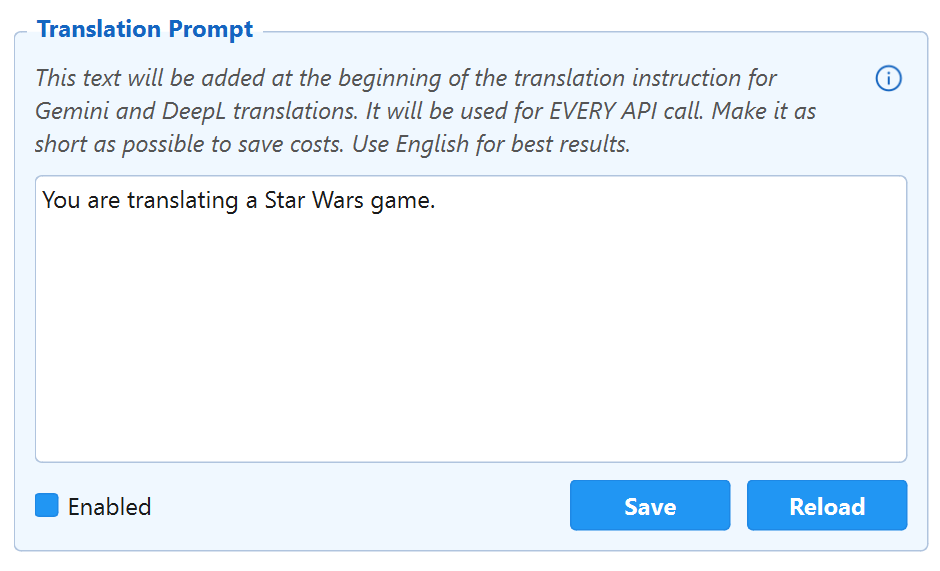
Translation Prompt Free
Inject a custom instruction into every translation request. Define the tone, style, or game-specific context to ensure consistent character names and immersive dialogue.
✍️
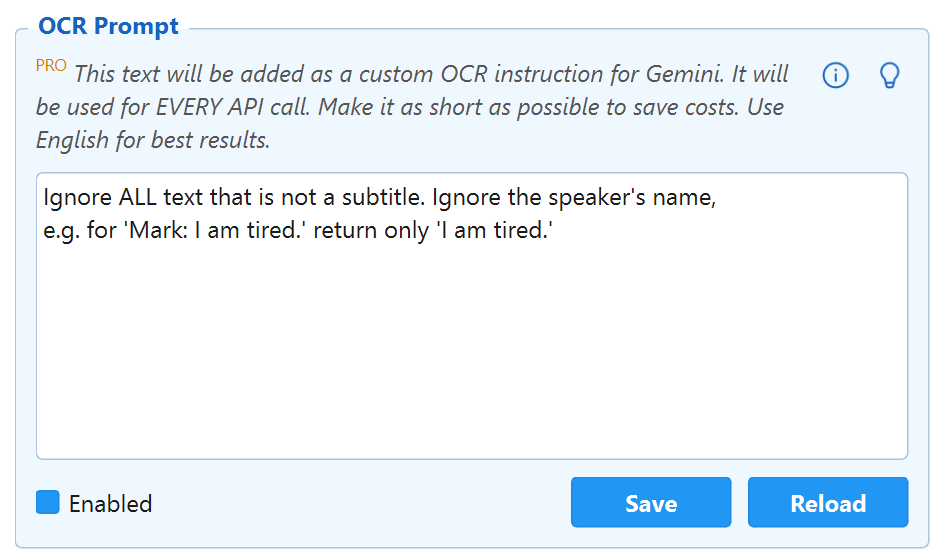
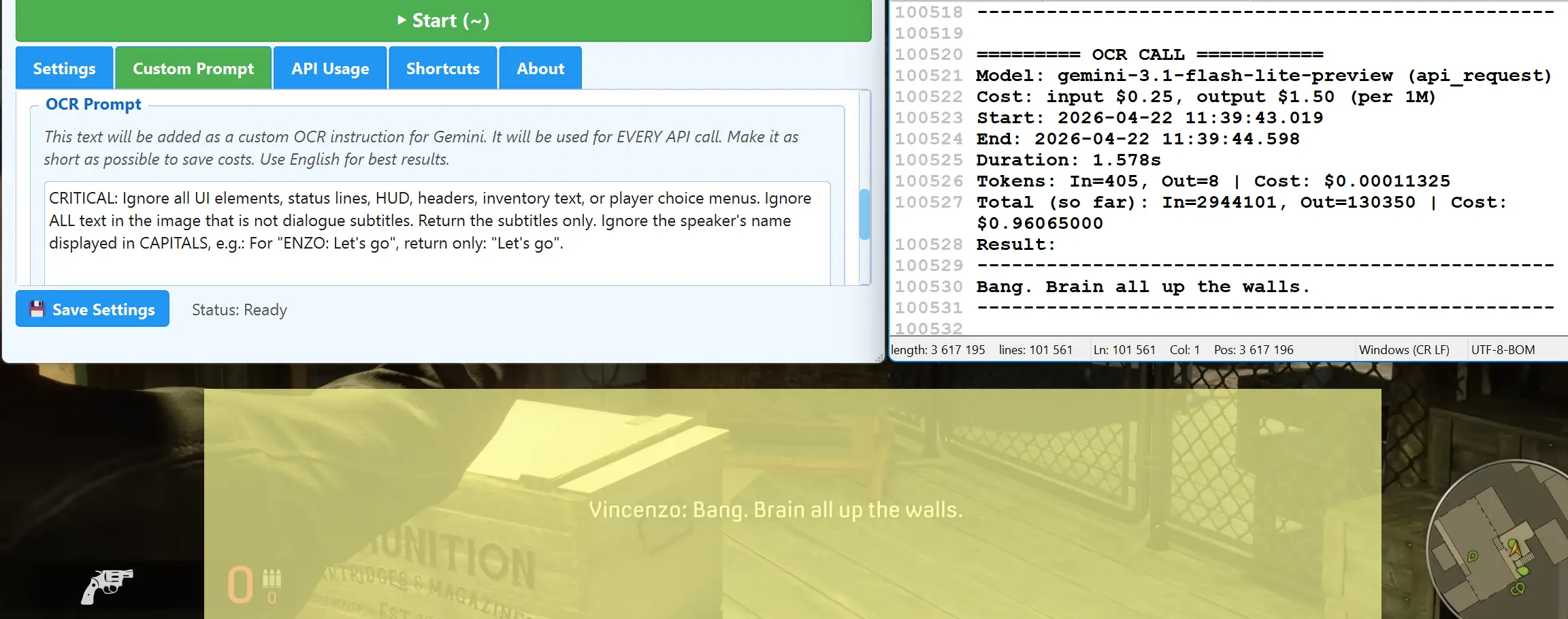
OCR Prompt PRO New v4
Inject a custom instruction into every AI OCR call – ignore HUD elements, strip speaker names, focus on dialogue only.
🖥️
New Redesigned GUI New v4
Fully redesigned interface with Simple and Custom modes. Clean, responsive, and self-contained. Built-in High-DPI scaling ensures a perfectly crisp and consistent interface across all screen resolutions.
🔡
Native RTL Support Free
The advanced native RTL engine powered by PySide6. Flawless character shaping, cursive joining, and bidirectional rendering for Arabic, Hebrew, Pashto, and Persian. Punctuation and numbering are handled with pixel-perfect accuracy.
📜
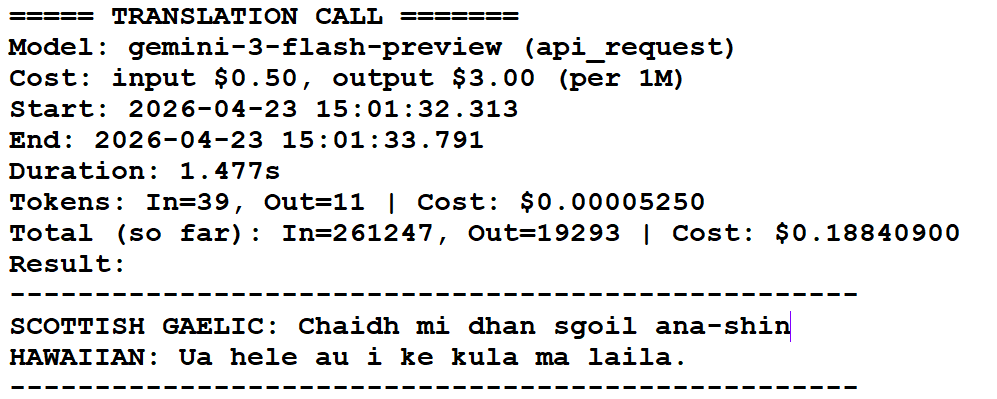
Translation API Logs Free
Unparalleled transparency with dual-layer logging. Short logs provide a quick overview of costs, while Long logs capture the entire API exchange – including system prompts, context subtitles, and raw model responses.
🖼️
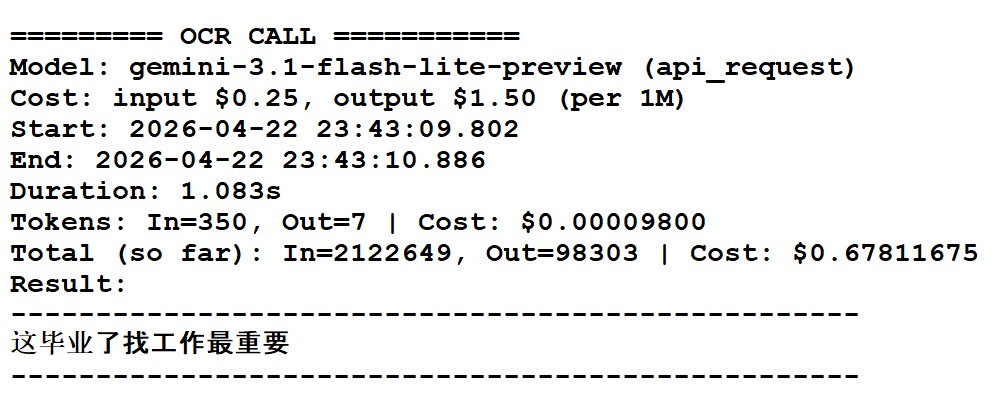
OCR API Logs Free
Comprehensive audit trail for every vision-based request. Track image metadata, token efficiency, and model latencies. Every recognition event is logged with its exact prompt, enabling precise debugging and cost monitoring.
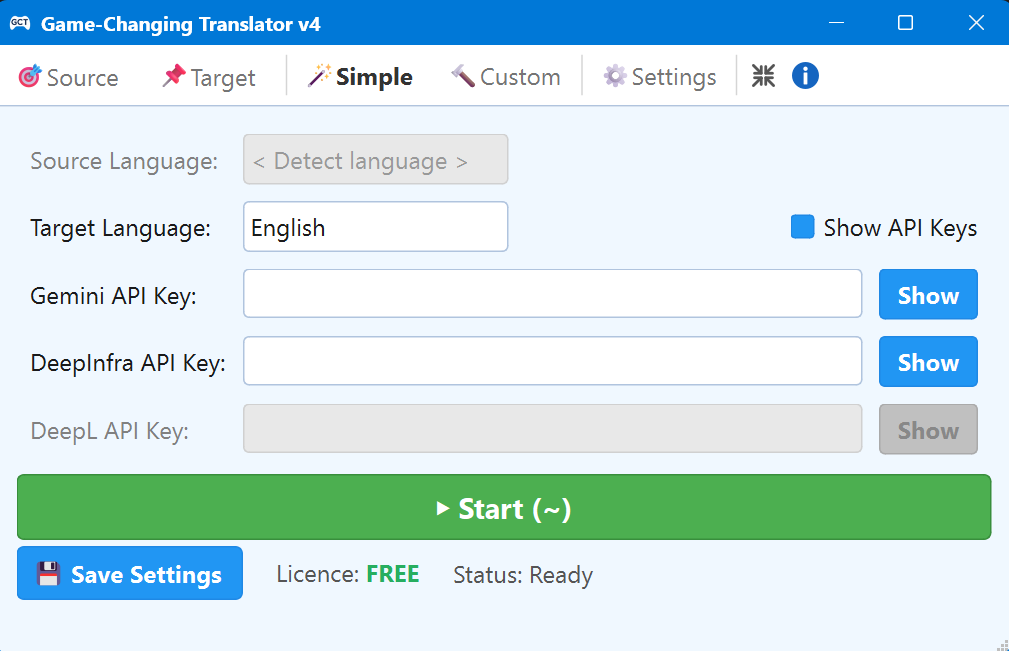


 /
/  icon, you can hide or show the language and API key fields.
icon, you can hide or show the language and API key fields.